近日,哈尔滨工程大学计算机科学与技术学院师生撰写的研究论文《Adaspeaker: Learning Discriminative Speaker Representations with Gradient-Aware Adaptive Scaling》被第33届国际多媒体大会ACM International Conference on Multimedia (ACM MM 2025)录用,会议将于2025年10月27-31日在爱尔兰都柏林举行。该会议由国际计算机学会(ACM)主办,是计算机科学领域顶级学术会议,CCF推荐A类会议。论文研究由2023级硕士生刘菁瀚(第一作者)在王兴梅老师(通讯作者)的指导下完成,论文作者还包括太原理工大学的孟稼祥老师。
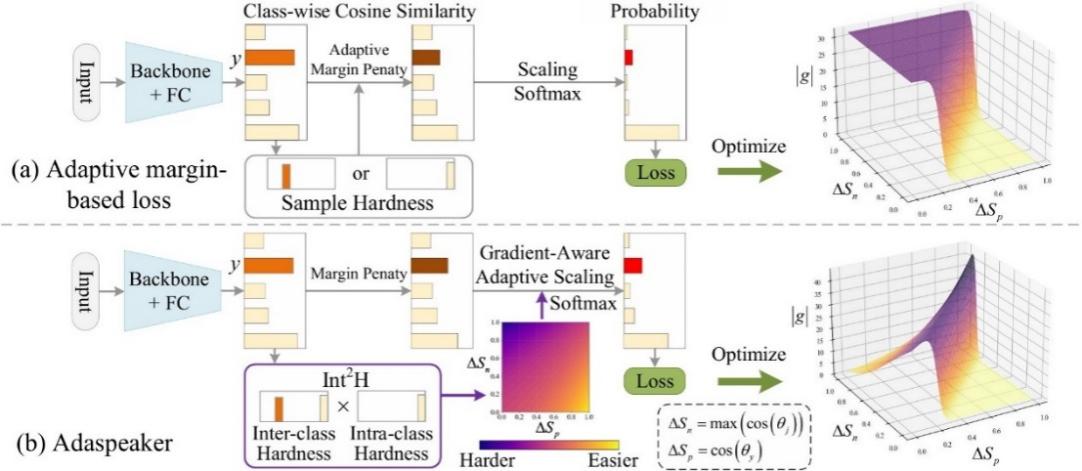
论文的研究内容聚焦于说话人识别,是多媒体音频信号处理的重要研究方向。为了提高说话人特征表示的判别性学习,当前先进的损失函数使用自适应边距策略强调重要的音频样本,虽然取得了性能的提升,但这类损失难以建立硬样本挖掘与梯度更新的显著关联。因此,该论文提出了一种新颖的损失函数,首先联合样本的类间难度与类内难度有效建模音频样本的难度系数,随后该系数用于自适应尺度化音频样本的余弦相似度预测以建立硬样本挖掘与梯度更新的显著关联。
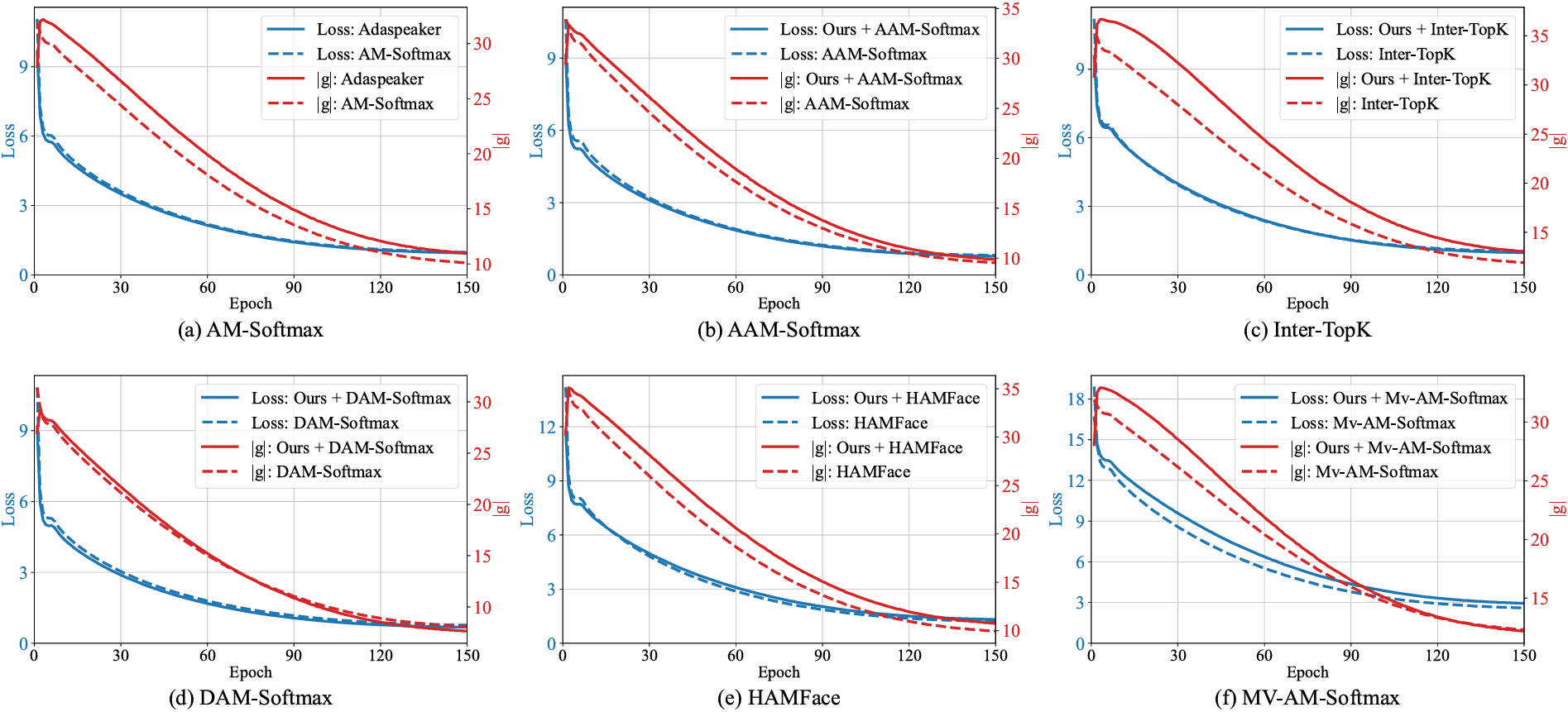
实验结果显示,所提出的自适应尺度化策略不仅可以有效强调重要样本的梯度贡献,而且可以集成至现有的自适应边距损失中,平均实现12.6%的性能提升。